
Building a react x electron code editor pt.4 - performance: memoizing and virtualization


recap
With a simple Lexer working to tokenise javascript code into tokens, we moved on to build a simple editor to view how the tokeniser works.
the structure
The 'editor' is actually a list of <div> tags which display <span> tags. These <span> tags have classNames which map to the tokens we extract in our lexer, and highlighted and coloured through CSS. The <Line/> component therefore looks like this:
export default function Line(props: LineProps) {
const lexer = useMemo(() => new Lexer(), [])
// Memoize the tokenisation operation on this Line.
const tokens = useMemo(() => {
// skip if plugin is null,
if (props.plugin !== null) {
return lexer.tokenise(props.value, props.plugin)
} else {
return []
}
},
// dep on the value or plugin,
[props.value, props.plugin])
return (
<div className="line">
{
tokens.map((token, index) =>
<span key={index}
className={'token ' + token.name}>
{token.value}
</span>)
}
</div>
)
}
So as the component is mounted the Lexer tokenises the line string and returns an array of tokens which map into the UI as <span> tags. You'll notice that every <span> has a base class token where it inherits the basic properties of the editor code token such as font-family, font-size...etc
thinking about performance
Once I started building the editor one thing became clear: performance is critical. When we write in an editor we want instant feedback in our screen, and parsing potentially thousands of lines with themselves hundreds of tokens is going to dramatically kill our machine generating html output.
The goal is with every user input to change the least possible UI needed, specially the components that are doing heavy duty processing such as the <Line/> components parsing potentially hundreds of tokens to render. We want operations to be O(1), regardless of the amount of lines in the file, instead of directly related to its length.
We can achieve this using the power of React. The first step is to memoize expensive operations that only need to change if a direct dependency changes, and the second is to virtualize our list of Lines.
memoizing
React has a very useful concept of Memos in its useMemo hook and React.Memo component API. It can do an expensive operation and know to not repeat unless a set of dependencies provided by you change explicitly.
For example in the editor the <Line/> component parsing is done in a useMemo hook:
const lexer = useMemo(() => new Lexer(), [])
// Memoize the tokenisation operation on this Line.
const tokens = useMemo(() => {
// skip if plugin is null,
if (props.plugin !== null) {
return lexer.tokenise(props.value, props.plugin)
} else {
return []
}
},
// dep on the value or plugin,
[props.value, props.plugin])
In this case we only want to tokenise the line again if the actual string value changes, or if we change our language plugin and we are not tokenising using the same language rules!
In small files around 80 lines or less, the editor is already performing decently, it takes a bit of time to render initially all the lines, but changing one line affects that one line only and editing text is fast.
virtualizing the list
What happens when the editor tries to parse a very big file, say 4000+ lines? Even though the DOM is pretty powerful nowadays trying to render 4000+ divs with potentially 20+ spans it quickly gets bogged down.
This is where virtualization comes in for lists, rendering a small visible subset of views and quickly replacing them as you scroll up or down with the necessary data.
There is already good virtual lists in react to look at:
However I realized I needed a custom implementation in order to be able to add directly UI overlays and have more fine tune control of the list.
from 4000 to 30
First step we want to achieve with a virtual list is to reduce the big data set to the least possible amount needed. Therefore we need to calculate in our list div how many <div> tags are actually going to be shown at any one point.
The list is actually composed of a small 'window' div which holds the actual massive div which can hold the whole dataset and which makes the window div overflow, aka scroll.
This is why we need a few props given to our <VirtualizedList/> component:
- windowHeight
- itemHeight
- itemCount
With these we can calculate how many items will show in the list 'window', and how big the containing list div will have to be.
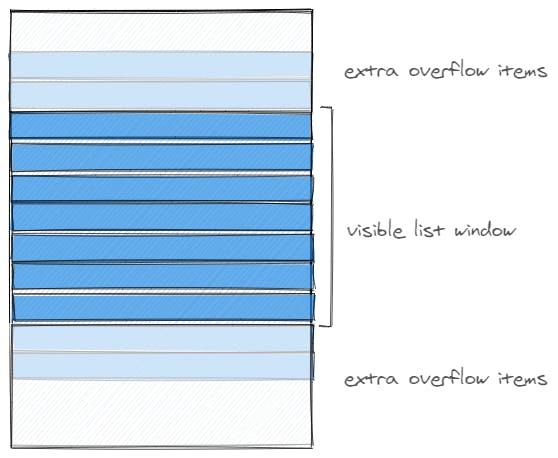
The virtualized list structure
It's typical to include some amount of 'overflow' items to the window visible items you render in order to reduce jankiness when scrolling really fast and the DOM not being able to replace items quick enough.
replace items on scroll
So with a number of items visible plus a few overflow extra, we have to know as we scroll the list div which 'virtual' items to display as opposed to our 'real' number of items. For example, as we scroll down and down, instead of showing the first 30 items all the time we need to show the 30 items of position 3600-3630, for example.
It's a case of finding the virtual index relative to the scrollTop property of the list div.
We can now assign to each virtual index its absolute position in the div to replace the divs position as we scroll:
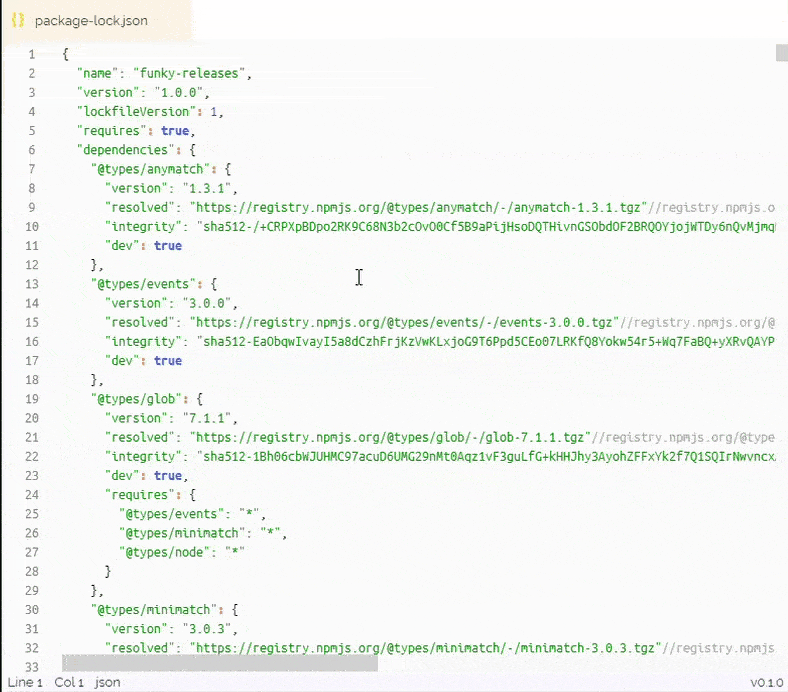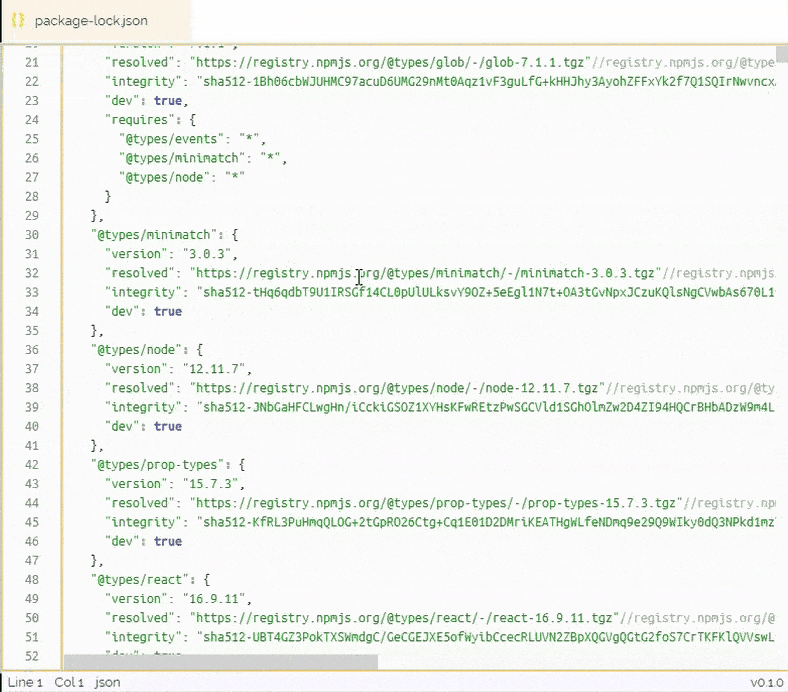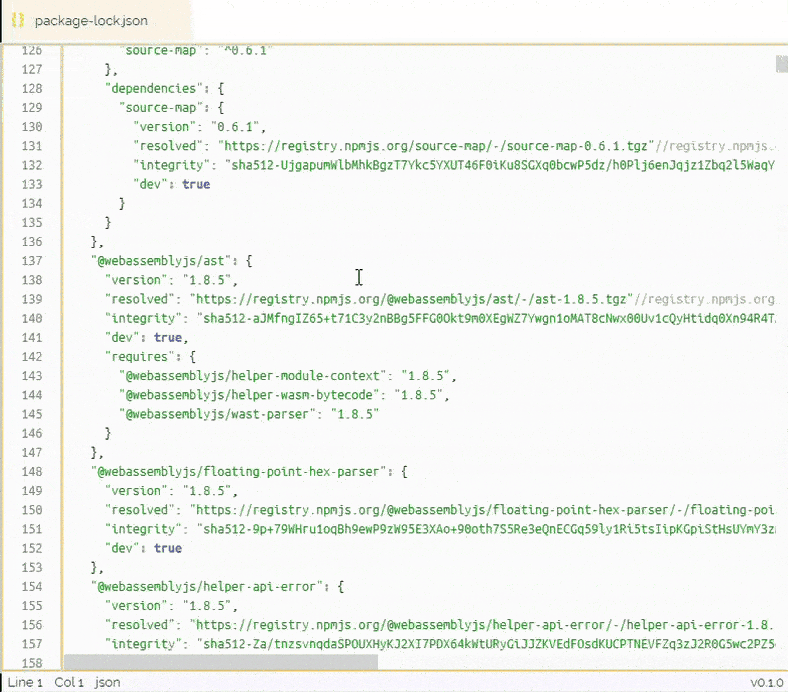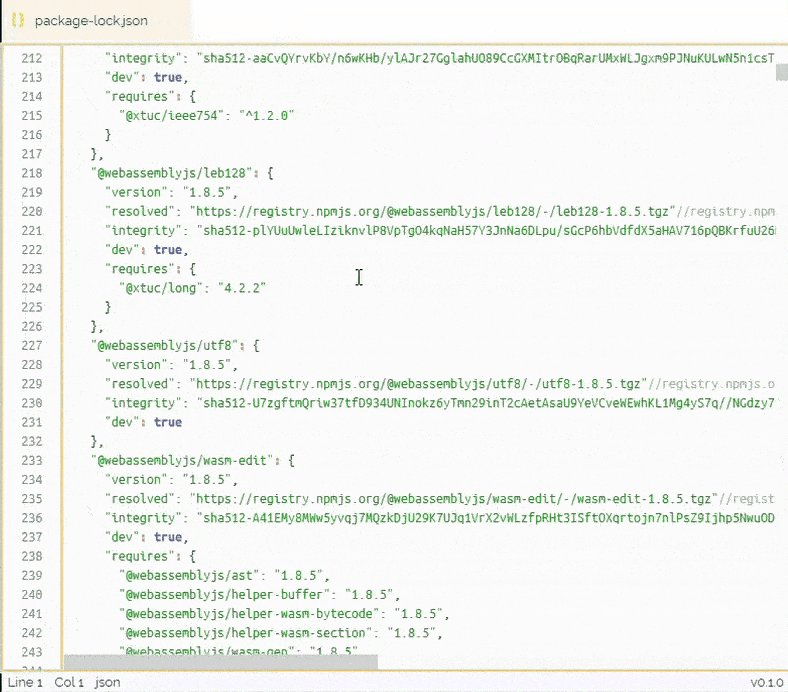
Here is a 3k line package.json being scrolled as if it was a small 80 line file. The performance is only directly related to how big the list window is, not the massive dataset!
next steps
With a decent viewer of our tokens it is time to give us some ability to edit them and write code!